
手写mysql连接池
关键技术点
MySQL数据库编程、单例模式、queue队列容器、C++11多线程编程、线程互斥、线程同步通信和 unique_lock、基于CAS的原子整形、智能指针shared_ptr、lambda表达式、生产者-消费者线程模型
语言层面实现以上技术,所以可以跨平台。
关于MySQL数据库(基于C/S设计):
每次连接时四次耗费性能的操作:tcp三次握手,四次挥手 ,mysql server连接认证,关闭连接回收资源
通用基础功能
初始连接量 initSize
最大连接量 maxSize:新创建的连接数量上限是maxSize,不能 无限制的创建连接,因为每一个连接都会占用一个socket资源,一般连接池和服务器程序是部署在一台 主机上的,如果连接池占用过多的socket资源,那么服务器就不能接收太多的客户端请求了。当这些连接使用完成后,再次归还到连接池当中来维护。
服务器进程:端口号
80(HTTP)或443(HTTPS) 数据库连接池:连接池是服务器程序(Web 服务器)内部的一个组件,它不对外提供端口,而是从服务器端发起数据库连接。 mysql数据库:端口号默认3306
最大空闲时间(maxIdleTime):当访问MySQL的并发请求多了以后,连接池里面的连接数量会动态 增加,上限是maxSize个,当这些连接用完再次归还到连接池当中。如果在指定的maxIdleTime里面, 这些新增加的连接都没有被再次使用过,那么新增加的这些连接资源就要被回收掉,只需要保持初始连 接量initSize个连接就可以了。
连接超时时间(connectionTimeout):当MySQL的并发请求量过大,连接池中的连接数量已经到达 maxSize了,而此时没有空闲的连接可供使用,那么此时应用从连接池获取连接无法成功,它通过 的方式获取连接的时间如果超过connectionTimeout时间 ( 期间一直试图获取 ),那么获取连接失败,无法访问数据库
具体代码
连接池:线程安全的懒汉单例
/*
实现连接池功能模块
1、连接池只需要一个实例->单例模式
2、服务端是多线程的->需要线程安全
*/
class ConnectionPool{
public:
//获取连接池对象实例
static ConnectionPool* getConnectionPool();
private:
ConnectionPool(); //构造函数私有化
};//线程安全的懒汉单例函数接口
ConnectionPool* ConnectionPool::getConnectionPool(){
static ConnectionPool pool;//编译器 自动进行 lock 和 unlock,天然的线程安全
return &pool;
}分析: 该函数 getConnectionPool() 作为 ConnectionPool 类的静态成员函数(static),可以在没有实例对象的情况下调用。
关键点:
- 局部静态变量(Local Static Variable):函数内的 static 变量在程序第一次调用该函数时初始化,并在整个程序生命周期内存续。
- C++11 及之后的标准规定:局部静态变量的初始化是线程安全的(由编译器自动加锁保证) 如果多个线程同时调用 getConnectionPool(),只有一个线程会执行初始化,其他线程会等待该初始化完成。
生产者线程
一个单独线程 1、在创建ConnectionPool时,启动生产者线程
//启动一个新的线程,作为连接的生产者 linux thread => pthread_create
thread produce(std::bind(&ConnectionPool::produceConnectionTask,this));std::thread 需要 可调用对象,但 produceConnectionTask 是成员函数,它需要 this 指针,不能直接使用。 可以C++11 Lambda 表达式替代 std::thread t([this] { this->produceConnectionTask(); });
2、produceConnectionTask方法 理解这里的生产者-消费者模型 注意锁的使用
//运行在独立的线程中,专门负责生产新连接
void ConnectionPool::produceConnectionTask(){
for(;;){
unique_lock<mutex> lock(_queueMutex);
// 加锁,消费者就拿不到锁了
while(!_connectionQue.empty()){
cv.wait(lock);//队列不空,此处生产线程进入等待状态
//把锁进行一个释放,消费者线程拿到这个锁,从队列取东西
}
//未到上限,继续创建新的创建
if(_connectionCnt<_maxSize){
Connection *p = new Connection();
p->connect(_ip,_port,_username,_password,_dbname);
//添加到队列里
_connectionQue.push(p);
_connectionCnt++;
}
//通知消费者线程,可以消费连接了
cv.notify_all();//消费者从等待到阻塞
}//锁释放,消费者拿到锁
}std::mutex(互斥量) 负责管理线程间的 独占访问。std::unique_lock是 智能锁,可以更灵活地管理std::mutex(支持手动lock()/unlock()、延迟加锁等)。std::unique_lock<std::mutex> lock(mtx);构造时自动加锁。作用域结束时 自动解锁(RAII 机制)。
关于条件变量condition_variable的wait , wait_for
消费者线程
非单独线程
//给外部提供接口,从连接池中获取一个可用的连接
shared_ptr<Connection> ConnectionPool::getConnection(){
unique_lock<mutex> lock(_queueMutex);
while(_connectionQue.empty()){
if(cv_status::timeout==cv.wait_for(lock,chrono::milliseconds(_connectionTimeout))){
//超时醒来,发现是空
if(_connectionQue.empty()){
LOG("获取空闲连接超时了..获取失败");
return nullptr;
}
}
}
/*
shared_ptr析构时,会把connection资源直接delete掉,相当于
调用connection的析构函数,connection就被close掉了。
这里需要自定义shared_ptr的释放资源的方式,把connection直接归还到queue中
*/
shared_ptr<Connection> sp(_connectionQue.front(),
[&](Connection* pcon){
// 这里是在服务器应用线程中调用的,所以一定要考虑队列的线程安全操作
unique_lock<mutex> lock(_queueMutex);
_connectionQue.push(pcon);
}
);
_connectionQue.pop();
// if(_connectionQue.empty()){
// cv.notify_all();
// 谁消费了队列中的最后一个连接,谁负责通知一下生产者生产连接
// }
cv.notify_all();//消费完连接以后,通知生产者线程检查一下,如果队列为空了,赶紧生产连接
return sp;
}注意使用shared_ptr, 不使用weak_ptr
weak_ptr不能直接使用,必须转换成shared_ptr,但如果资源已释放,则转换失败。weak_ptr不能自定义删除行为,无法自动归还连接池。
最大空闲时间回收连接扫描线程
detach()的作用: 线程与 scanner 对象分离。scanner 对象本身会立即销毁,但线程不会受影响,它仍然会在后台运行,直到 scannerConnectionTask 结束。
//扫描超过maxIdleTime时间的空闲连接,进行连接回收
void ConnectionPool::scannerConnectionTask(){
for(;;){
//通过sleep模拟定时效果
this_thread::sleep_for(chrono::seconds(_maxIdleTime));
//扫描整个队列,释放多余的连接
unique_lock<mutex> lock(_queueMutex);
while(_connectionCnt>_initSize){
Connection *p = _connectionQue.front();
if(p->getAliveTime()>=_maxIdleTime*1000){
_connectionQue.pop();
_connectionCnt--;
delete p;//调用~Connection()释放连接
}else{
break;//队头的连接没有超过maxIdleTime,其他连接肯定没有
}
}
}
}编译运行命令与注意事项🔺
项目基础部分:
├── include
│ ├── Connection.h
│ ├── ConnectionPool.h
│ └── public.h
├── main
├── README.md
└── src
├── Connection.cpp
├── ConnectionPool.cpp
└── main.cpp编译命令: g++ src/*.cpp -o main -Iinclude -L/usr/lib/x86_64-linux-gnu -lmysqlclient
包括:
/usr/lib//usr/lib/x86_64-linux-gnu//lib/x86_64-linux-gnu//usr/local/lib/
libmysqlclient.so,因为它是一个外部库,而不是标准库(如 libc)。你必须显式告诉编译器去链接这个库。(第一个是-I,第二个是-l)
运行: ./main
加载配置文件时: FILE *pf = fopen("mysql.cnf","r");
这个mysql.cnf放置位置应该与 执行文件 main 在同一级目录下,即mysql.cnf并非与源代码文件在同一级目录下
ConnectionPool.h中包含了 Connection.h,那么main.cpp中仅包含ConnetionPool.h即可,不再包含Connetion.h,否则出现类的重定义问题。
性能测试
涉及优化的项目都得进行 压力 性能测试,
函数说明:返回从开始程序进程到调用clock()之间的CPU时钟计时单元(clock tick)数,即硬件滴答数 硬件滴答数需要换算成s或者ms,通过头文件time.h或者ctime中的CLOCKS_PER_SEC来实现,该值在windows下为1000,在标准POSIX下为1000000,即每过CLOCKS_PER_SEC个滴答数,即为1s
未使用连接池:
int main(){
clock_t begin = clock();
for(int i=0;i<1000;i++){
Connection conn;
char sql[1024]={0};
string s = "testt"+to_string(i);
// cout<<s.c_str()<<endl;
sprintf(sql,"insert into user(name,password) values('%s','%s')",s.c_str(),"123");
conn.connect("127.0.0.1",3306,"root","123456","chat");
conn.update(sql);
}
clock_t end =clock();
double endtime=(double)(end-begin)/CLOCKS_PER_SEC;
cout<<"Over time:"<< endtime * 1000<< "ms" << endl;
return 0;
}注意
运行后,出现了以下问题: 1、每次程序运行时只能在数据库中插入了150到160条左右的数据,后面的都显示“插入失败” 2、最后输出的结果为6000多ms,远多于教学视频中的1000多ms。
Answer 1: 数据库最大连接数 max_connection 的限制。 经查询:SHOW VARIABLES LIKE 'max_connections',可以看到其值为151 => 通过 SET GLOBAL max_connections = 1000; 临时增加最大连接数(重启 MySQL 后会恢复) =>再测试,1000条数据成功插入,但是打印输出 41174.3ms? Answer 2: 可能是硬件原因
使用连接池后:
clock_t begin = clock();
ConnectionPool *cp = ConnectionPool::getConnectionPool();
for(int i=0;i<1000;i++){
shared_ptr<Connection>sp= cp->getConnection();
char sql[1024]={0};
string s = "testt"+to_string(i);
// cout<<s.c_str()<<endl;
sprintf(sql,"insert into user(name,password) values('%s','%s')",s.c_str(),"123");
sp->update(sql);
}
clock_t end =clock();
double endtime=(double)(end-begin)/CLOCKS_PER_SEC;
cout<<"Over time:"<< endtime * 1000<< "ms" << endl;
return 0;打印输出: 1000条数据 824.255ms 5000条数据 2570.7ms 10000条 4776.06ms
连接池+多线程
//多线程
thread t1([](){
ConnectionPool *cp = ConnectionPool::getConnectionPool();
for(int i=0;i<2500;i++){
shared_ptr<Connection>sp= cp->getConnection();
char sql[1024]={0};
string s = "testt"+to_string(i);
// cout<<s.c_str()<<endl;
sprintf(sql,"insert into user(name,password) values('%s','%s')",s.c_str(),"123");
sp->update(sql);
}
});
thread t2([](){
ConnectionPool *cp = ConnectionPool::getConnectionPool();
for(int i=0;i<2500;i++){
shared_ptr<Connection>sp= cp->getConnection();
char sql[1024]={0};
string s = "testt"+to_string(i);
// cout<<s.c_str()<<endl;
sprintf(sql,"insert into user(name,password) values('%s','%s')",s.c_str(),"123");
sp->update(sql);
}
});
thread t3([](){
ConnectionPool *cp = ConnectionPool::getConnectionPool();
for(int i=0;i<2500;i++){
shared_ptr<Connection>sp= cp->getConnection();
char sql[1024]={0};
string s = "testt"+to_string(i);
// cout<<s.c_str()<<endl;
sprintf(sql,"insert into user(name,password) values('%s','%s')",s.c_str(),"123");
sp->update(sql);
}
});
thread t4([](){
ConnectionPool *cp = ConnectionPool::getConnectionPool();
for(int i=0;i<2500;i++){
shared_ptr<Connection>sp= cp->getConnection();
char sql[1024]={0};
string s = "testt"+to_string(i);
// cout<<s.c_str()<<endl;
sprintf(sql,"insert into user(name,password) values('%s','%s')",s.c_str(),"123");
sp->update(sql);
}
});
t1.join();
t2.join();
t3.join();
t4.join();| 数据量 | 未使用连接池 | 使用连接池 | ||
|---|---|---|---|---|
| 1000 | 单线程:41174.3ms | 四线程: | 单线程: 824.255ms | 四线程 |
| 5000 | 单线程: | 四线程: | 单线程: 2570.7ms | 四线程: |
| 10000 | 单线程: | 四线程: | 单线程: 4779.06ms | 四线程:5077.35ms |
注意: 把user表的name列唯一索引(unique key)给去掉:alter table user drop index name; 这样多线程才方便插入成功(不会因为不唯一而插入失败)
注意
Q:为什么使用多线程却没有加快??? 猜想一:可能是线程切换开销。 更可能的猜想:与内核设置相关
修改Linux虚拟机内核设置后再测试
查看虚拟机的处理器内核数 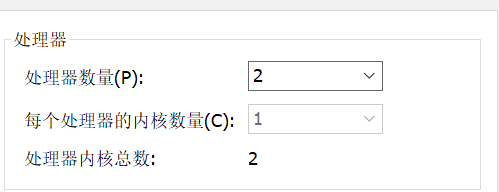
处理器内核总数=处理器数量✖每个处理器的内核数量 此处虚拟机的处理器内核总数对应于真实物理机(或者叫宿主机)的CPU线程数(即逻辑处理器的数量)。
所以在设置的时候,我们只要让处理器内核总数<逻辑处理器的数量即可。
查看自己电脑的参数 
第一个为内核数量,第二个为逻辑处理器数量。
【一个CPU可以有多个内核,一个内核一般对应于一个线程,但是通过Intel的超线程技术,一个核心可以对应于两个线程,即可以并行处理两个任务,所以逻辑处理器的数量是内核数量的两倍】
那么尝试设置内核总数为16 的一半 :8
修改内核为1x8后
因为宿主机的CPU是单颗处理器(1个物理CPU), 所以设置处理器个数1,每个处理器内核数量8。因为不支持超线程,故线程数同样为8 
再测试: 使用连接池, 数据量10000 , => 四线程,Over time:4756.56ms;单线程 13405.6ms
| 数据量 | 未使用连接池 | 使用连接池 | ||
|---|---|---|---|---|
| 1000 | 单线程: | 四线程: | 单线程: | 四线程 |
| 5000 | 单线程: | 四线程: | 单线程: | 四线程: |
| 10000 | 单线程: | 四线程: | 单线程: 13405.6ms | 四线程:4756.56ms |
修改内核为2x4后
修改内核为2 x 4 后,测试未使用连接池的性能,还是 40149.4ms,非常高
| 数据量 | 未使用连接池 | 使用连接池 | ||
|---|---|---|---|---|
| 1000 | 单线程:40149.4ms | 四线程:84529.7ms | 单线程: | 四线程 |
| 5000 | 单线程: | 四线程: | 单线程: | 四线程: |
| 10000 | 单线程: | 四线程: | 单线程:5183.99ms ,5225.29ms | 四线程:4500.29ms,4897.86ms |
性能测试总结
为了测试使用连接池对于访问数据库的性能提升,进行了是否使用连接池和是否是多线程的对照测试。 在不使用连接池下测试时,发现一开始会插入失败,通过排查发现每次只能成功插入150条到160条数据,原因是数据库最大连接量max_connection=151,更改为1000后能成功插入。
在未使用连接池时,每次for循环内需要重新进行tcp的3次握手,4次挥手,mysql server认证,关闭连接释放资源等耗时操作,所以测出的耗时远比使用连接池的高。(也有本地电脑硬件限制的原因)
在使用连接池后,因为内核的设置不同,而呈现出不同的测试结果。 在1w条数据下: 2x1 | 单线程: 4779.06ms | 四线程:5077.35ms | 1x8 | 单线程: 13405.6ms | 四线程:4756.56ms | 2x4 | 单线程:5183.99ms ,5225.29ms | 四线程:4500.29ms,4897.86ms |
会发现有时候多线程反而比单线程慢(可能因为线程调度开销)
总的来说,2×4 在四线程下表现最佳,表明 多核多处理器结构更有利于数据库连接池的并发处理。